
【行业】中国人工智能基础数据服务白皮书(43页)
2019-09-29
人工智能基础数据服务意指为AI算法训练及优化提供数据采集和标注等形式的服务。人工智能基础数据服务指为AI算法训练及优化提供的数据采集、清洗、信息抽取、标注等服务,以采集和标注为主。人工智能概念爆发伊始,算法、算力、数据就作为最重要的三要素被人们乐道,进入落地阶段,智能交互、人脸识别、无人驾驶等应用成为了最大的热门,AI公司开始比拼技术与产业的结合能力,而数据作为AI算法的“燃料”,是实现这一能力的必要条件,因此,为机器学习算法训练、优化提供数据采集、标注等服务的人工智能基础数据服务成为了这一人工智能热潮中必不可少的一环。如果说计算机工程师是AI的老师,那基础数据服务就是老师手中的教材。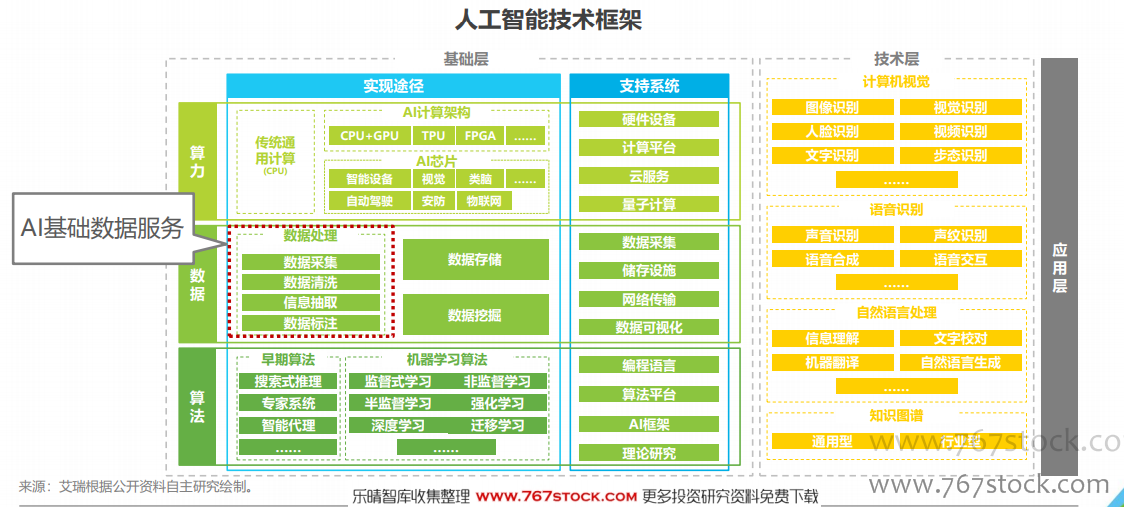 行业进入成长期,行业格局逐渐清晰。伴随国内人工智能热潮爆发,大量的AI公司拿到融资,为了不断提高算法精度,数据采标需求也空前爆发,一度催生了行业的繁荣。但早期的AI基础数据服务门槛较低,玩家鱼龙混杂,使行业标准模糊、服务质量参差不齐。随着竞争加快,AI公司对训练数据的质量要求也不断提高,并且当产业落地成为主旋律,需求方对垂直场景的定制化数据采标需求成为主流,众多小型AI基础数据服务公司从数据质量和采标能力上达不到要求,或被淘汰,或依附大平台,行业格局逐渐清晰,头部公司实力逐渐凸显。随着算法需求越来越旺盛,目前机器辅助标注、人工主要标注的手段需要改进提升,增强数据处理平台持续学习和自学习能力,增加机器能够标注维度、提升机器处理数据的精度,由机器承担主要标注工作将成为下一阶段的行业重心。未来,越来越多的长尾、小概率事件所产生的数据需求增强,人机协作标注的模式性价比不足,机器模拟或机器生成数据会是解决这一问题的良好途径,及早研发相应技术也将成为AI基础数据服务商未来的护城河。
行业进入成长期,行业格局逐渐清晰。伴随国内人工智能热潮爆发,大量的AI公司拿到融资,为了不断提高算法精度,数据采标需求也空前爆发,一度催生了行业的繁荣。但早期的AI基础数据服务门槛较低,玩家鱼龙混杂,使行业标准模糊、服务质量参差不齐。随着竞争加快,AI公司对训练数据的质量要求也不断提高,并且当产业落地成为主旋律,需求方对垂直场景的定制化数据采标需求成为主流,众多小型AI基础数据服务公司从数据质量和采标能力上达不到要求,或被淘汰,或依附大平台,行业格局逐渐清晰,头部公司实力逐渐凸显。随着算法需求越来越旺盛,目前机器辅助标注、人工主要标注的手段需要改进提升,增强数据处理平台持续学习和自学习能力,增加机器能够标注维度、提升机器处理数据的精度,由机器承担主要标注工作将成为下一阶段的行业重心。未来,越来越多的长尾、小概率事件所产生的数据需求增强,人机协作标注的模式性价比不足,机器模拟或机器生成数据会是解决这一问题的良好途径,及早研发相应技术也将成为AI基础数据服务商未来的护城河。 目前有监督的深度学习是主流,标注数据是其学习根本。人工智能是研究如何通过机器来模拟人类认知能力的科学,机器学习是现阶段实现人工智能的主要手段。机器学习方法通常是从已知数据中学习规律或者判断规则,建立预测模型,其中,深度学习可以通过对低层特征的组合,形成更加抽象的高层属性类别,自动从信息中学习有效的特征并进行分类,而无需人为选取特征。凭借自动提取特征、神经网络结构、端到端学习等优势,深度学习在图像和语音领域学习效果最佳,是当今最热门的算法架构。在实际应用中,深度学习算法多采用有监督学习模式,即需要标注数据对学习结果进行反馈,在大量数据训练下,算法错误率能大大降低。现在的人脸识别、自动驾驶、语音交互等应用都采用这类方法训练,对于各类标注数据有着海量需求,可以说数据资源决定了当今人工智能的高度。由于应用有监督学习的AI算法对于标注数据的需求远大于现有的标注效率和投入预算,无监督或仅需要少量标注数据的弱监督学习、小样本学习成为了科学家探索的方向,但目前无论从学习效果和使用边界来看,均不能有效替代有监督学习,人工智能基础数据服务将持续释放其对于人工智能的基础支撑价值。
目前有监督的深度学习是主流,标注数据是其学习根本。人工智能是研究如何通过机器来模拟人类认知能力的科学,机器学习是现阶段实现人工智能的主要手段。机器学习方法通常是从已知数据中学习规律或者判断规则,建立预测模型,其中,深度学习可以通过对低层特征的组合,形成更加抽象的高层属性类别,自动从信息中学习有效的特征并进行分类,而无需人为选取特征。凭借自动提取特征、神经网络结构、端到端学习等优势,深度学习在图像和语音领域学习效果最佳,是当今最热门的算法架构。在实际应用中,深度学习算法多采用有监督学习模式,即需要标注数据对学习结果进行反馈,在大量数据训练下,算法错误率能大大降低。现在的人脸识别、自动驾驶、语音交互等应用都采用这类方法训练,对于各类标注数据有着海量需求,可以说数据资源决定了当今人工智能的高度。由于应用有监督学习的AI算法对于标注数据的需求远大于现有的标注效率和投入预算,无监督或仅需要少量标注数据的弱监督学习、小样本学习成为了科学家探索的方向,但目前无论从学习效果和使用边界来看,均不能有效替代有监督学习,人工智能基础数据服务将持续释放其对于人工智能的基础支撑价值。
行业进入成长期,行业格局逐渐清晰。伴随国内人工智能热潮爆发,大量的AI公司拿到融资,为了不断提高算法精度,数据采标需求也空前爆发,一度催生了行业的繁荣。但早期的AI基础数据服务门槛较低,玩家鱼龙混杂,使行业标准模糊、服务质量参差不齐。随着竞争加快,AI公司对训练数据的质量要求也不断提高,并且当产业落地成为主旋律,需求方对垂直场景的定制化数据采标需求成为主流,众多小型AI基础数据服务公司从数据质量和采标能力上达不到要求,或被淘汰,或依附大平台,行业格局逐渐清晰,头部公司实力逐渐凸显。随着算法需求越来越旺盛,目前机器辅助标注、人工主要标注的手段需要改进提升,增强数据处理平台持续学习和自学习能力,增加机器能够标注维度、提升机器处理数据的精度,由机器承担主要标注工作将成为下一阶段的行业重心。未来,越来越多的长尾、小概率事件所产生的数据需求增强,人机协作标注的模式性价比不足,机器模拟或机器生成数据会是解决这一问题的良好途径,及早研发相应技术也将成为AI基础数据服务商未来的护城河。
目前有监督的深度学习是主流,标注数据是其学习根本。人工智能是研究如何通过机器来模拟人类认知能力的科学,机器学习是现阶段实现人工智能的主要手段。机器学习方法通常是从已知数据中学习规律或者判断规则,建立预测模型,其中,深度学习可以通过对低层特征的组合,形成更加抽象的高层属性类别,自动从信息中学习有效的特征并进行分类,而无需人为选取特征。凭借自动提取特征、神经网络结构、端到端学习等优势,深度学习在图像和语音领域学习效果最佳,是当今最热门的算法架构。在实际应用中,深度学习算法多采用有监督学习模式,即需要标注数据对学习结果进行反馈,在大量数据训练下,算法错误率能大大降低。现在的人脸识别、自动驾驶、语音交互等应用都采用这类方法训练,对于各类标注数据有着海量需求,可以说数据资源决定了当今人工智能的高度。由于应用有监督学习的AI算法对于标注数据的需求远大于现有的标注效率和投入预算,无监督或仅需要少量标注数据的弱监督学习、小样本学习成为了科学家探索的方向,但目前无论从学习效果和使用边界来看,均不能有效替代有监督学习,人工智能基础数据服务将持续释放其对于人工智能的基础支撑价值。



