
【行业】AIGC-2023年有望成为AIGC的拐点(19页)
2023-02-10
AIGC(AI-Generated Content)是利用人工智能技术来生成内容。2021 年之前,AIGC生成的主要还是文字,而新一代模型可以处理的格式内容包括:文字、语音、代码、图像、视频、机器人动作等等。AIGC 被认为是继专业生产内容(PGC,professional-generatedcontent)、用户生产内容(UGC,User-generated content)之后的新型内容创作方式,可以在创意、表现力、迭代、传播、个性化等方面,充分发挥技术优势。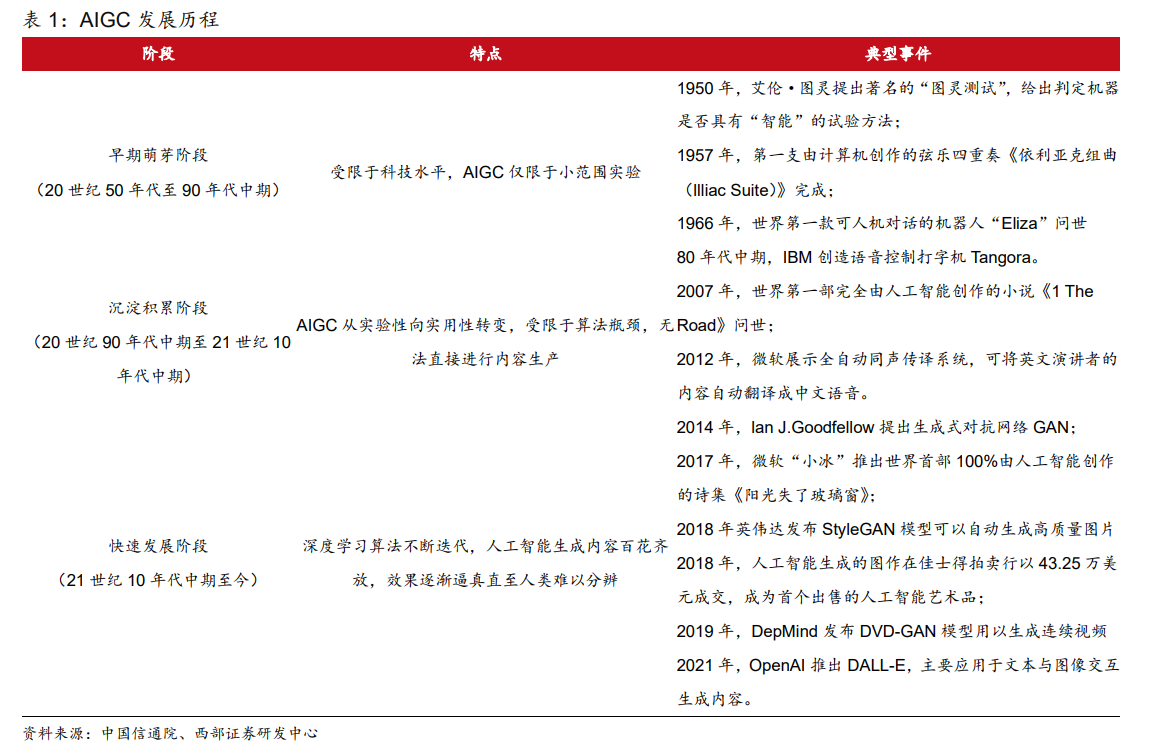 但是 GAN 有三个不足:1)对输出结果的控制力较弱,容易产生随机图像;2)生成的图像分别率较低;3)由于 GAN 需要用判别器来判断生产的图像是否与其他图像属于同一类别,这就导致生成的图像是对现有作品的模仿,而非创新。因此依托 GAN 模型难以创作出新图像,也不能通过文字提示生成新图像。
但是 GAN 有三个不足:1)对输出结果的控制力较弱,容易产生随机图像;2)生成的图像分别率较低;3)由于 GAN 需要用判别器来判断生产的图像是否与其他图像属于同一类别,这就导致生成的图像是对现有作品的模仿,而非创新。因此依托 GAN 模型难以创作出新图像,也不能通过文字提示生成新图像。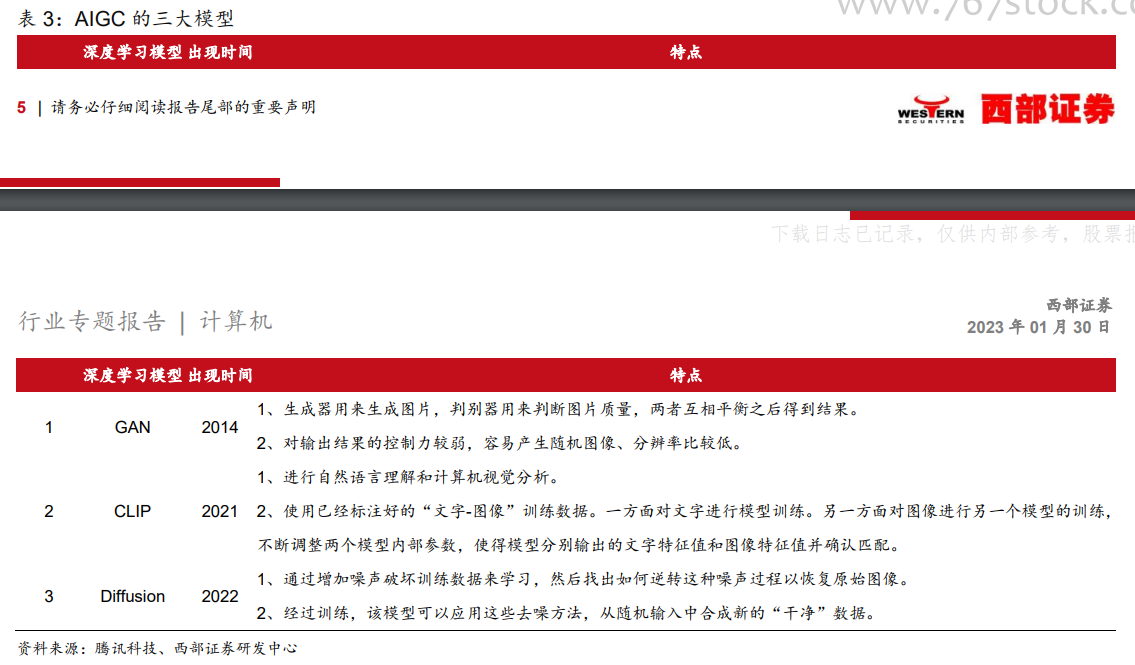 CLIP 模型能够将文字和图像进行关联,比如将文字“狗”和狗的图像进行关联,并且关联的特征非常丰富。因此,CLIP 模型具备两个优势:1)同时进行自然语言理解和计算机视觉分析,实现图像和文本匹配。2)为了有足够多标记好的“文本-图像”进行训练,CLIP模型广泛利用互联网上的图片,这些图片一般都带有各种文本描述,成为 CLIP 天然的训练样本。据腾讯科技公众号显示,CLIP 模型搜集了网络上超过 40 亿个“文本-图像”训练数据,这为后续 AIGC 尤其是输入文本生成图像/视频应用的落地奠定了基础。
CLIP 模型能够将文字和图像进行关联,比如将文字“狗”和狗的图像进行关联,并且关联的特征非常丰富。因此,CLIP 模型具备两个优势:1)同时进行自然语言理解和计算机视觉分析,实现图像和文本匹配。2)为了有足够多标记好的“文本-图像”进行训练,CLIP模型广泛利用互联网上的图片,这些图片一般都带有各种文本描述,成为 CLIP 天然的训练样本。据腾讯科技公众号显示,CLIP 模型搜集了网络上超过 40 亿个“文本-图像”训练数据,这为后续 AIGC 尤其是输入文本生成图像/视频应用的落地奠定了基础。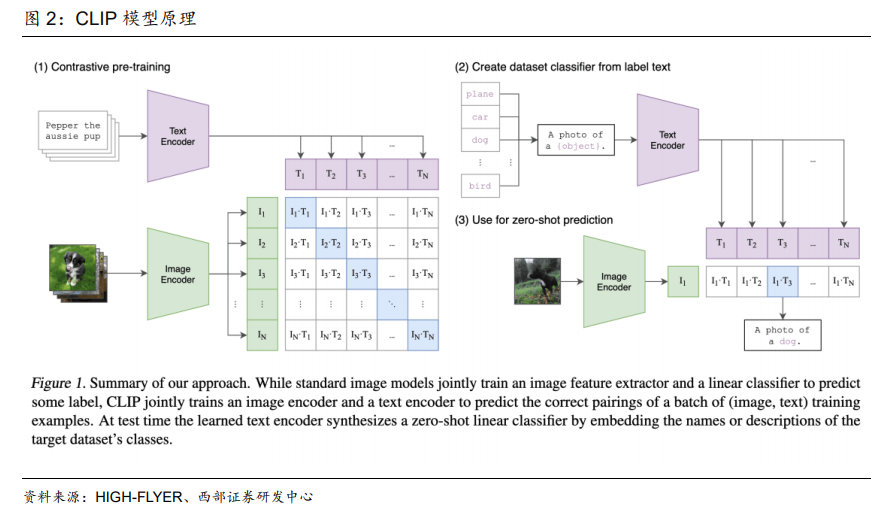
但是 GAN 有三个不足:1)对输出结果的控制力较弱,容易产生随机图像;2)生成的图像分别率较低;3)由于 GAN 需要用判别器来判断生产的图像是否与其他图像属于同一类别,这就导致生成的图像是对现有作品的模仿,而非创新。因此依托 GAN 模型难以创作出新图像,也不能通过文字提示生成新图像。CLIP 模型能够将文字和图像进行关联,比如将文字“狗”和狗的图像进行关联,并且关联的特征非常丰富。因此,CLIP 模型具备两个优势:1)同时进行自然语言理解和计算机视觉分析,实现图像和文本匹配。2)为了有足够多标记好的“文本-图像”进行训练,CLIP模型广泛利用互联网上的图片,这些图片一般都带有各种文本描述,成为 CLIP 天然的训练样本。据腾讯科技公众号显示,CLIP 模型搜集了网络上超过 40 亿个“文本-图像”训练数据,这为后续 AIGC 尤其是输入文本生成图像/视频应用的落地奠定了基础。



